- Archives


-
Logiciels de gestion de versions par: larbi khaoula Publié le Mercredi 30 Mars 2011 à 19:06:49
- CVS
- Subversion : http://subversion.tigris.org
- Visual SourceSafe (Société Microsoft)
- Perforce
- ClearCase (Société Rational Software/IBM)
- PVCS(Dimensions): http://www.serena.com/
- SCCS
- RCS
- GNU Arch : http://www.gnu.org/software/gnu-arch/
- Bazaar : http://bazaar.canonical.com (compatible avec GNU Arch) et son lointain descendant Bazaar-ng : http://www.bazaar-ng.org
- Synergy (Société Telelogic)
- Bitkeeper
- SCM Surround (Société Seapine)
- DaRCS : http://www.darcs.net/
- git, utilisé entre autres pour le noyau GNU/linux
- Mercurial : http://www.selenic.com/mercurial
- So6, logiciel de gestion de configuration (La gestion de configuration consiste à gérer la description technique d'un système[1] (et de ses divers composants), ainsi qu'à gérer l'ensemble des modifications apportées au cours de l'évolution du système. La gestion de configuration est utilisée pour la gestion de systèmes complexes :) de LibreSource
- MECASP, gestion de versions et fusion (En physique et en métallurgie, la fusion est le passage d'un corps de l'état solide vers l'état liquide. Pour un corps pur, c’est-à-dire pour une substance constituée de molécules toutes identiques, la fusion s'effectue à température constante. La température de fusion ou de solidification d'un...) de variantes : http://mecasp.free.fr
- SVK, basé sur le système de fichier de Subversion : http://svk.elixus.org/
- MKS : http://www.mks.com/
- Vault (Société SourceGear)
- Monotone
- ALDON Lifecycle Manager (Société ALDON): http://www.aldon.fr
- JediVCS http://jedivcs.sourceforge.net/
Afficher les 4 commentaires. Dernier par Messoud Samar le 05-04-2011 à 01h46 - Permalien -
Avec l'arrivée des logiciels libres et leur développement communautaire, une autre façon de voir la gestion de versions est apparue. Cette autre vision consiste à voir l'outil de gestion de versions comme un outil permettant à chacun de travailler à son rythme, de façon désynchronisée des autres, puis d'offrir un moyen à ces développeurs de s'échanger leur travaux respectifs. C'est ce que l'on nomme la gestion de versions décentralisée.
Mercurial, Darcs, Bazaar, Git, Monotone, GNU Arch et BitKeeper (propriétaire) sont des logiciels de gestion de versions décentralisée. Avec ceux-ci, il existe plusieurs dépôts de versions et aucun n'a de statut privilégié.
Avantages de la Gestion de version décentralisée :
* permet aux contributeurs de travailler sans être connecté au gestionnaire de version,
* la plupart des opérations sont plus rapides car réalisée en local (sans accès réseau),
* permet la participation à un projet sans nécessiter les permissions par un responsable du projet (les droits de commit peuvent donc être donnés après avoir démontré son travail et non pas avant),
* permet le travail privé pour réaliser des brouillons sans devoir publier ses modifications et gêner les autres contributeurs,
* permet de ne pas être dépendant d'une seule machine comme point de défaillance,
* permet toutefois de garder un dépôt de référence contenant les versions livrées d'un projet
Désavantages :
* cloner un dépôt est plus long que récupérer une version pour une gestion de version décentralisée car tout l'historique est copié (ce qui est toutefois un avantage par la suite).
* il n'y a pas de système de lock (ce qui peut poser des problèmes pour des données binaires qui ne se mergent pas)
L'auteur de développement logiciel Joel Spolsky décrit la gestion de version décentralisée comme "probablement la plus grande avancée dans les technologies de développement logiciel dans les 10 [dernières] années."
Avec l'arrivée des logiciels libres et leur développement communautaire, une autre façon de voir la gestion de versions est apparue. Cette autre vision consiste à voir l'outil de gestion de versions comme un outil permettant à chacun de travailler à son rythme, de façon désynchronisée des autres, puis d'offrir un moyen à ces développeurs de s'échanger leur travaux respectifs. C'est ce que l'on nomme la gestion de versions décentralisée.
Mercurial, Darcs, Bazaar, Git, Monotone, GNU Arch et BitKeeper (propriétaire) sont des logiciels de gestion de versions décentralisée. Avec ceux-ci, il existe plusieurs dépôts de versions et aucun n'a de statut privilégié.
Avantages de la Gestion de version décentralisée :
* permet aux contributeurs de travailler sans être connecté au gestionnaire de version,
* la plupart des opérations sont plus rapides car réalisée en local (sans accès réseau),
* permet la participation à un projet sans nécessiter les permissions par un responsable du projet (les droits de commit peuvent donc être donnés après avoir démontré son travail et non pas avant),
* permet le travail privé pour réaliser des brouillons sans devoir publier ses modifications et gêner les autres contributeurs,
* permet de ne pas être dépendant d'une seule machine comme point de défaillance,
* permet toutefois de garder un dépôt de référence contenant les versions livrées d'un projet
Désavantages :
* cloner un dépôt est plus long que récupérer une version pour une gestion de version décentralisée car tout l'historique est copié (ce qui est toutefois un avantage par la suite).
* il n'y a pas de système de lock (ce qui peut poser des problèmes pour des données binaires qui ne se mergent pas)
L'auteur de développement logiciel Joel Spolsky décrit la gestion de version décentralisée comme "probablement la plus grande avancée dans les technologies de développement logiciel dans les 10 [dernières] années."
cvs Publié le Mercredi 30 Mars 2011 à 18:36:27Réalisé par Jarboui Lobna
Exemple de gestion de version :
CVS : Concurrent Versions System est un système de gestion de versions, successeur de SCCS(Source Code Control System) originalement écrit par Dick Grune en 1986, puis complété par Brian Berliner (avec le programme cvs lui-même) en 1989, et par la suite amélioré par de très nombreux contributeurs. Puisqu'il aide les sources à converger vers la même destination, on dira que CVS fait la gestion concurrente de versions ou de la gestion de versions concurrentes. Il peut aussi bien fonctionner en mode ligne de commande qu'à travers une interface graphique. Il se compose de modules clients et d'un ou plusieurs modules serveur pour les zones d'échanges.
En effet, CVS est un système de contrôle de versions de fichiers. Le serveur CVS permet de conserver l'historique de toutes les modifications successives et de leur description, des fichiers placés sous son contrôle (généralement du code source) et de leur description. Le serveur CVS dispose d'un mécanisme intelligent de fusion des modifications apportées sur des fichiers texte, ce qui permet de gérer l'édition de fichiers par plusieurs auteurs en parallèle et de gérer les conflits possibles, de déclencher des actions (mail, scripts, ...) à différents moments du cycle de vie des fichiers ou du projet. Nous pouvons obtenir des images des projets aux différents moments de leur vie (version majeure, mise à jour, correctif, ...). Par exemple nous pouvons récupérer très simple la version 1.x d'un projet y apporter des modifications, et dans le même temps revenir à la version principale et continuer son travail.
Horloge système et synchronisation
L'horloge du serveur et toutes les machines clientes devront être synchronisées à l'aide de Network Time Protocol (un protocole qui permet de synchroniser via un réseau informatique, l'horloge locale d'ordinateurs sur une référence d'heure), en effet CVS se sert de l'heure et de la date pour effectuer ses opérations et cela est capital pour l'intégrité de la base CVS. En effet le serveur CVS effectuant des comparaisons entre les différentes versions du fichier, des écarts de dates entre les différents postes, mettront en péril l'intégrité de la base CVS.
Le dépôt (repository)
Le dépôt est la base centralisée de CVS à savoir les fichiers d'administration se trouvant dans le sous dossier CVSROOT ainsi que les dossiers des différents projets (livres, développements, sites web, ...). Ce répertoire peut se trouver n'importe où sur le système de fichiers (ex: /usr/local/cvsroot) et le chemin pour l'atteindre doit être défini dans la variable d'environnement $CVSROOT. Afin que chaque utilisateur d'un groupe de travail puisse travailler sur un projet, le dossier ($CVSROOT/nom_projet) devra avoir les droits en lecture et écriture sur le groupe ainsi que le bit s positionné (garanti que chaque fichier/dossier cré appartient au groupe), il en sera de même pour /var/lock/cvs/nom_projet.
Initialisation du dépôt
 Dans le cas on installe CVS pour la première fois, ou qu’on n’a pas de dépôt. Une fois la variable d'environnement CVSROOT définie, sur le serveur, on lance la commande :
Dans le cas on installe CVS pour la première fois, ou qu’on n’a pas de dépôt. Une fois la variable d'environnement CVSROOT définie, sur le serveur, on lance la commande :mkdir /usr/local/cvsroot
cvs init
ou pour plus de contrôle sur la création du dépôt :cvs -d /usr/local/cvsroot init
chown -R cvs:cvs /usr/local/cvsrootchmod g+rwxs /usr/local/cvsroot/CVSROOT Pour les accès en mode connecté, vous devrez ensuite créer le fichier $CVSROOT/CVSROOT/passwd ayant la structure suivante:
Pour les accès en mode connecté, vous devrez ensuite créer le fichier $CVSROOT/CVSROOT/passwd ayant la structure suivante:login_CVS:[mot_de_passe_crypt][:login_systeme]
Ce fichier étant particulièrement sensible il est préférable de ne pas mettre les mêmes mots de passe que ceux pour se connecter au serveur et de donner les droit suivants au fichier passwd de cvs.chmod 400 $CVSROOT/CVSROOT/passwd
c'est un des rares cas où vous irez modifier un fichier dans $CVSROOT/CVSROOT. L'accès se fait par l'utilisation des commandes CVS.
Configuration du serveur CVS
Accédez au serveur avec un utilisateur faisant partie du groupe cvs.mkdir ~/Projets/
cd ~/Projets/
cvs -d /usr/local/cvsroot checkout CVSROOT
 si la variable CVSROOT est définie l'option -d /usr/local/cvsroot est facultative
si la variable CVSROOT est définie l'option -d /usr/local/cvsroot est facultative-rw-rw-r-- 1 jmj jmj 495 mai 17 01:49 checkoutlist
-rw-rw-r-- 1 jmj jmj 760 mai 17 01:49 commitinfo
-rw-rw-r-- 1 jmj jmj 986 mai 17 02:35 config
drwxr-xr-x 2 jmj jmj 4096 mai 23 19:01 CVS/
-rw-rw-r-- 1 jmj jmj 602 mai 17 01:49 cvswrappers
-rw-rw-r-- 1 jmj jmj 1025 mai 17 01:49 editinfo-rw-rw-r-- 1 jmj jmj 1141 mai 17 01:49 loginfo
-rw-rw-r-- 1 jmj jmj 1151 mai 17 01:49 modules
-rw-rw-r-- 1 jmj jmj 564 mai 17 01:49 notify
-rw-rw-r-- 1 jmj jmj 649 mai 17 01:49 rcsinfo
-rw-rw-r-- 1 jmj jmj 879 mai 17 01:49 taginfo
-rw-rw-r-- 1 jmj jmj 1026 mai 17 01:49 verifymsg
Modifiez le fichier config :
cd CVSROOTvi config
# Exemple de fichier config
SystemAuth=noLockDir=/var/lock/cvsTopLevelAdmin=noLogHistory=TOEFWUPCGMARRereadLogAfterVerify=always Validez les modifications
Validez les modificationscvs commit -m "Configuration initiale de CVS" configAccès au dépôt
L'accès à cette base CVS peut s'effectuer de 5 manières différentes:
Direct
Les fichiers dans ce cas doivent être accessible directement au travers du système de fichier ou d'un système de fichier réparti tel que NFS ou SMB. Dans ce cas nous utilisons CVS en mode non connecté.CVSROOT=:local:/usr/local/cvsroot ou CVSROOT=/usr/local/cvsroot
Serveur
 Le serveur CVS est en attente des requêtes clientes, sur le port TCP 2401. A ajouter dans /etc/services:
Le serveur CVS est en attente des requêtes clientes, sur le port TCP 2401. A ajouter dans /etc/services:cvspserver 2401/tcp # CVS client/server operations
dans /etc/inetd.conf si vous utilisez inetdcvspserver stream tcp nowait cvs /usr/bin/cvs cvs –allow root=/usr/local /cvsroot pserver
 pour qu'inetd prenne en compte les changements dans son fichier de configuration
pour qu'inetd prenne en compte les changements dans son fichier de configurationkillall -HUP inetd
 si vous utilisez xinetd
si vous utilisez xinetd# CVS configuration for xinetd don't forget to specify your CVSROOT in
# /etc/cvs/cvs.conf.service cvspserver
{disable = nosocket_type = stream
protocol = tcp
wait = no
user = root
passenv = PATH
 server = /usr/sbin/cvspserver
server = /usr/sbin/cvspserverserver_args = -f --allow-root=/usr/local/cvsroot pserver
}
 pour que xinetd prenne en compte les changements :
pour que xinetd prenne en compte les changements :killall -HUP xinetd
Sur la machine cliente définir la variable CVSROOTCVSROOT=:pserver:user@server:/usr/local/cvsroot
L'authentification est réalisée grâce à la commande :cvs login
qui enregistrera le mot de passe sous forme chiffrée dans le fichier .cvspass si la connexion est acceptée (pour changer le nom du fichier.cvspass, définissez le dans $CVS_PASSFILE). Pour que la connexion aboutisse, ce fichier devra également exister dans $CVROOT/passwd
L'algorithme ci-dessous explicite l'utilisation que fait pserver de ces fichier pour décider d'accorder un droit d'accès en lecture seule ou en lecture-écriture à l'utilisateur user.
SI user n'existe pas dans le fichier passwd OU son mot de passe est incorrect ALORS ACCES REFUSE
SINON SI le fichier readers existe ET user y figure ALORS -> ACCES LECTURE SEULE
SINON SI le fichier writers existe ET user n'y figure pas ALORS -> ACCES LECTURE SEULE SINON -> ACCES LECTURE-ECRITURE FINSI
Kerberos
 Le serveur CVS est en attente sur le port TCP 1999 ajoutez dans /etc/services:
Le serveur CVS est en attente sur le port TCP 1999 ajoutez dans /etc/services:cvskserver 1999/tcp dans inetd.conf
dans inetd.confcvskserver stream tcp nowait cvs /usr/bin/cvs cvs --allow-root=/usr/local/cvsroot kserver
 Sur la machine cliente définir la variable CVSROOT
Sur la machine cliente définir la variable CVSROOTCVSROOT=:kserver:server:/usr/local/cvsroot
sur la machine cliente utilisez kinit pour obtenir un ticket kerberos vous permettant ensuite de vous connecter et d'utiliser les commandes cvs.
GSSAPI
 Permet d'accéder à des systèmes sécurisés tel que kerberos 5. CVS et ses outils auront été compilés préalablement en incluant le support GSSAPI (option --with-gssapi). Ce mode est équivalent au mode serveur et utilise également le fichier $CVSROOT/passwd. Par défaut les communications ne sont ni authentifiées ni chiffrées et il faudra utiliser des options spéciales de CVS (voir détail des commandes man et info). Sur la machine cliente définir la variable CVSROOT
Permet d'accéder à des systèmes sécurisés tel que kerberos 5. CVS et ses outils auront été compilés préalablement en incluant le support GSSAPI (option --with-gssapi). Ce mode est équivalent au mode serveur et utilise également le fichier $CVSROOT/passwd. Par défaut les communications ne sont ni authentifiées ni chiffrées et il faudra utiliser des options spéciales de CVS (voir détail des commandes man et info). Sur la machine cliente définir la variable CVSROOTCVSROOT=:gserver:server:/usr/local/cvsrootrsh et ssh
Dans ce mode le client accède au serveur en utilisant rsh. Sur la machine cliente définir la variable CVSROOTCVSROOT=:ext:user@server:/usr/local/cvsroot
Vérifier que la commande rsh fonctionne indépendamment de cvs.rsh -l user server uname -a
Il faudrait configurer rsh pour ne pas demander à chaque fois le mot de passe (.rhosts ou encore host.equiv), mais cette méthode n'est pas du tout sécurisée, nous utiliserons ssh en remplacement de rsh. Définissez la variable d'environnement CVS_RSHCVS_RSH=ssh
 Vous devrez mettre votre clef publique dans ~/.ssh/authorized_keys sur le serveur pour ne plus entrer le mot de passe à chaque fois. Nous retiendrons ce mode ou shell sécurisé utilisant kerberos pour toutes communications distantes afin d'éviter d'exposer votre système à des attaques, en chiffrant les connexions et les transferts de données.
Vous devrez mettre votre clef publique dans ~/.ssh/authorized_keys sur le serveur pour ne plus entrer le mot de passe à chaque fois. Nous retiendrons ce mode ou shell sécurisé utilisant kerberos pour toutes communications distantes afin d'éviter d'exposer votre système à des attaques, en chiffrant les connexions et les transferts de données.# depuis le poste client$ ssh-keygen -t dsa # PubkeyAuthentication : clé DSA pour SSH2
$ cat .ssh/id_dsa.pub | ssh user1@remote"cat - >>.ssh/authorized_keys[2]"Modules
 Chaque projet que vous ajoutez dans CVS correspond à un module. Pour ajouter un module
Chaque projet que vous ajoutez dans CVS correspond à un module. Pour ajouter un modulemkdir /usr/local/cvsroot/nom_projet && mkdir /var/lock/cvs/nom_projet
chowm cvs:groupe_du_projet /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
chmod g+rwxs /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
Les commandes principales de CVS
- cvs login (pour se connecter en mode client server)
- cvs logout (pour se déconnecter en mode client server)
- cvs import -m "Liste nouveaux composants" nom_projet/HOWTO LFO V1 (ajoute les fichiers du répertoire courant avec le vendeur-tag LFO et le release-tag V1, sans avoir de copie de travail et évite de recourir aux sous-commandes add et commit pour tous les fichiers et répertoires ajoutés)
- cvs checkout nom_projet (récupère en local le module nom_projet)
- cvs update (met à jour les fichiers de la copie de travail en local)
- cvs status -v nom_fichier (visualise l'état et les noms de versions symboliques du fichier)
- cvs -n update (idem que cvs status mais les informations sont plus condensées)
- cvs add -m (ajout de la procédure d'installation" INSTALL, ajoute le fichier INSTALL)
- cvs remove -f nom_fichier (supprime physiquement et dans la base CVS nom_fichier), pour être validée cette commande devra être suivie d'un cvs commit
- cvs commit -m "première version" index.html (archive la version dans CVS)
- cvs export -k v -d version_prod -r STABLE-V1_1 nom_projet (extrait une copie du module nom_projet dans le répertoire projet_v1_1 sans les répertoires de gestion utilisés par CVS)
- cd nom_projet/srv_server & cvs tag SRV-V1_0 (défini le nom symbolique SRV-V1_0 pour tous les fichiers de nom_projet/srv_server)
- cvs co -r SRV-V1_0 nom_projet/srv_server (récupère les fichiers ayant le tag SRV-V1_0 de nom_projet/srv_server)
- cvs rtag SRV-V2_0 nom_projet (défini le nom symbolique SRV-V2_0 à la dernière version présente dans la base des fichiers du module nom_projet)
- cvs diff --ifdef=V1_2 -r1.1 -r1.3 index.html (affiche les différences entre les versions 1.1 et 1.3 en séparant les modifications par le symbole préprocesseur V1_2)
- cvs rdiff -s -r STABLE-V1_0 nom_projet (résume les différences entre la version S Exemple de gestion de version :
CVS : Concurrent Versions System est un système de gestion de versions, successeur de SCCS(Source Code Control System) originalement écrit par Dick Grune en 1986, puis complété par Brian Berliner (avec le programme cvs lui-même) en 1989, et par la suite amélioré par de très nombreux contributeurs. Puisqu'il aide les sources à converger vers la même destination, on dira que CVS fait la gestion concurrente de versions ou de la gestion de versions concurrentes. Il peut aussi bien fonctionner en mode ligne de commande qu'à travers une interface graphique. Il se compose de modules clients et d'un ou plusieurs modules serveur pour les zones d'échanges.
En effet, CVS est un système de contrôle de versions de fichiers. Le serveur CVS permet de conserver l'historique de toutes les modifications successives et de leur description, des fichiers placés sous son contrôle (généralement du code source) et de leur description. Le serveur CVS dispose d'un mécanisme intelligent de fusion des modifications apportées sur des fichiers texte, ce qui permet de gérer l'édition de fichiers par plusieurs auteurs en parallèle et de gérer les conflits possibles, de déclencher des actions (mail, scripts, ...) à différents moments du cycle de vie des fichiers ou du projet. Nous pouvons obtenir des images des projets aux différents moments de leur vie (version majeure, mise à jour, correctif, ...). Par exemple nous pouvons récupérer très simple la version 1.x d'un projet y apporter des modifications, et dans le même temps revenir à la version principale et continuer son travail.
Horloge système et synchronisation
L'horloge du serveur et toutes les machines clientes devront être synchronisées à l'aide de Network Time Protocol (un protocole qui permet de synchroniser via un réseau informatique, l'horloge locale d'ordinateurs sur une référence d'heure), en effet CVS se sert de l'heure et de la date pour effectuer ses opérations et cela est capital pour l'intégrité de la base CVS. En effet le serveur CVS effectuant des comparaisons entre les différentes versions du fichier, des écarts de dates entre les différents postes, mettront en péril l'intégrité de la base CVS.
Le dépôt (repository)
Le dépôt est la base centralisée de CVS à savoir les fichiers d'administration se trouvant dans le sous dossier CVSROOT ainsi que les dossiers des différents projets (livres, développements, sites web, ...). Ce répertoire peut se trouver n'importe où sur le système de fichiers (ex: /usr/local/cvsroot) et le chemin pour l'atteindre doit être défini dans la variable d'environnement $CVSROOT. Afin que chaque utilisateur d'un groupe de travail puisse travailler sur un projet, le dossier ($CVSROOT/nom_projet) devra avoir les droits en lecture et écriture sur le groupe ainsi que le bit s positionné (garanti que chaque fichier/dossier cré appartient au groupe), il en sera de même pour /var/lock/cvs/nom_projet.
Initialisation du dépôt
Dans le cas on installe CVS pour la première fois, ou qu’on n’a pas de dépôt. Une fois la variable d'environnement CVSROOT définie, sur le serveur, on lance la commande :mkdir /usr/local/cvsroot
cvs init
ou pour plus de contrôle sur la création du dépôt :cvs -d /usr/local/cvsroot init
chown -R cvs:cvs /usr/local/cvsrootchmod g+rwxs /usr/local/cvsroot/CVSROOTPour les accès en mode connecté, vous devrez ensuite créer le fichier $CVSROOT/CVSROOT/passwd ayant la structure suivante:login_CVS:[mot_de_passe_crypt][:login_systeme]
Ce fichier étant particulièrement sensible il est préférable de ne pas mettre les mêmes mots de passe que ceux pour se connecter au serveur et de donner les droit suivants au fichier passwd de cvs.chmod 400 $CVSROOT/CVSROOT/passwd
c'est un des rares cas où vous irez modifier un fichier dans $CVSROOT/CVSROOT. L'accès se fait par l'utilisation des commandes CVS.
Configuration du serveur CVS
Accédez au serveur avec un utilisateur faisant partie du groupe cvs.mkdir ~/Projets/
cd ~/Projets/
cvs -d /usr/local/cvsroot checkout CVSROOT
si la variable CVSROOT est définie l'option -d /usr/local/cvsroot est facultative-rw-rw-r-- 1 jmj jmj 495 mai 17 01:49 checkoutlist
-rw-rw-r-- 1 jmj jmj 760 mai 17 01:49 commitinfo
-rw-rw-r-- 1 jmj jmj 986 mai 17 02:35 config
drwxr-xr-x 2 jmj jmj 4096 mai 23 19:01 CVS/
-rw-rw-r-- 1 jmj jmj 602 mai 17 01:49 cvswrappers
-rw-rw-r-- 1 jmj jmj 1025 mai 17 01:49 editinfo-rw-rw-r-- 1 jmj jmj 1141 mai 17 01:49 loginfo
-rw-rw-r-- 1 jmj jmj 1151 mai 17 01:49 modules
-rw-rw-r-- 1 jmj jmj 564 mai 17 01:49 notify
-rw-rw-r-- 1 jmj jmj 649 mai 17 01:49 rcsinfo
-rw-rw-r-- 1 jmj jmj 879 mai 17 01:49 taginfo
-rw-rw-r-- 1 jmj jmj 1026 mai 17 01:49 verifymsg
Modifiez le fichier config :
cd CVSROOTvi config
# Exemple de fichier config
SystemAuth=noLockDir=/var/lock/cvsTopLevelAdmin=noLogHistory=TOEFWUPCGMARRereadLogAfterVerify=alwaysValidez les modificationscvs commit -m "Configuration initiale de CVS" configAccès au dépôt
L'accès à cette base CVS peut s'effectuer de 5 manières différentes:
Direct
Les fichiers dans ce cas doivent être accessible directement au travers du système de fichier ou d'un système de fichier réparti tel que NFS ou SMB. Dans ce cas nous utilisons CVS en mode non connecté.CVSROOT=:local:/usr/local/cvsroot ou CVSROOT=/usr/local/cvsroot
Serveur
Le serveur CVS est en attente des requêtes clientes, sur le port TCP 2401. A ajouter dans /etc/services:cvspserver 2401/tcp # CVS client/server operations
dans /etc/inetd.conf si vous utilisez inetdcvspserver stream tcp nowait cvs /usr/bin/cvs cvs –allow root=/usr/local /cvsroot pserver
pour qu'inetd prenne en compte les changements dans son fichier de configurationkillall -HUP inetd
si vous utilisez xinetd# CVS configuration for xinetd don't forget to specify your CVSROOT in
# /etc/cvs/cvs.conf.service cvspserver
{disable = nosocket_type = stream
protocol = tcp
wait = no
user = root
passenv = PATH
server = /usr/sbin/cvspserverserver_args = -f --allow-root=/usr/local/cvsroot pserver
}
pour que xinetd prenne en compte les changements :killall -HUP xinetd
Sur la machine cliente définir la variable CVSROOTCVSROOT=:pserver:user@server:/usr/local/cvsroot
L'authentification est réalisée grâce à la commande :cvs login
qui enregistrera le mot de passe sous forme chiffrée dans le fichier .cvspass si la connexion est acceptée (pour changer le nom du fichier.cvspass, définissez le dans $CVS_PASSFILE). Pour que la connexion aboutisse, ce fichier devra également exister dans $CVROOT/passwd
L'algorithme ci-dessous explicite l'utilisation que fait pserver de ces fichier pour décider d'accorder un droit d'accès en lecture seule ou en lecture-écriture à l'utilisateur user.
SI user n'existe pas dans le fichier passwd OU son mot de passe est incorrect ALORS ACCES REFUSE
SINON SI le fichier readers existe ET user y figure ALORS -> ACCES LECTURE SEULE
SINON SI le fichier writers existe ET user n'y figure pas ALORS -> ACCES LECTURE SEULE SINON -> ACCES LECTURE-ECRITURE FINSI
Kerberos
Le serveur CVS est en attente sur le port TCP 1999 ajoutez dans /etc/services:cvskserver 1999/tcpdans inetd.confcvskserver stream tcp nowait cvs /usr/bin/cvs cvs --allow-root=/usr/local/cvsroot kserver
Sur la machine cliente définir la variable CVSROOTCVSROOT=:kserver:server:/usr/local/cvsroot
sur la machine cliente utilisez kinit pour obtenir un ticket kerberos vous permettant ensuite de vous connecter et d'utiliser les commandes cvs.
GSSAPI
Permet d'accéder à des systèmes sécurisés tel que kerberos 5. CVS et ses outils auront été compilés préalablement en incluant le support GSSAPI (option --with-gssapi). Ce mode est équivalent au mode serveur et utilise également le fichier $CVSROOT/passwd. Par défaut les communications ne sont ni authentifiées ni chiffrées et il faudra utiliser des options spéciales de CVS (voir détail des commandes man et info). Sur la machine cliente définir la variable CVSROOTCVSROOT=:gserver:server:/usr/local/cvsrootrsh et ssh
Dans ce mode le client accède au serveur en utilisant rsh. Sur la machine cliente définir la variable CVSROOTCVSROOT=:ext:user@server:/usr/local/cvsroot
Vérifier que la commande rsh fonctionne indépendamment de cvs.rsh -l user server uname -a
Il faudrait configurer rsh pour ne pas demander à chaque fois le mot de passe (.rhosts ou encore host.equiv), mais cette méthode n'est pas du tout sécurisée, nous utiliserons ssh en remplacement de rsh. Définissez la variable d'environnement CVS_RSHCVS_RSH=ssh
Vous devrez mettre votre clef publique dans ~/.ssh/authorized_keys sur le serveur pour ne plus entrer le mot de passe à chaque fois. Nous retiendrons ce mode ou shell sécurisé utilisant kerberos pour toutes communications distantes afin d'éviter d'exposer votre système à des attaques, en chiffrant les connexions et les transferts de données.# depuis le poste client$ ssh-keygen -t dsa # PubkeyAuthentication : clé DSA pour SSH2
$ cat .ssh/id_dsa.pub | ssh user1@remote"cat - >>.ssh/authorized_keys[2]"Modules
Chaque projet que vous ajoutez dans CVS correspond à un module. Pour ajouter un modulemkdir /usr/local/cvsroot/nom_projet && mkdir /var/lock/cvs/nom_projet
chowm cvs:groupe_du_projet /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
chmod g+rwxs /usr/local/cvsroot/nom_projet /var/lock/cvs/nom_projet
Les commandes principales de CVS
- cvs login (pour se connecter en mode client server)
- cvs logout (pour se déconnecter en mode client server)
- cvs import -m "Liste nouveaux composants" nom_projet/HOWTO LFO V1 (ajoute les fichiers du répertoire courant avec le vendeur-tag LFO et le release-tag V1, sans avoir de copie de travail et évite de recourir aux sous-commandes add et commit pour tous les fichiers et répertoires ajoutés)
- cvs checkout nom_projet (récupère en local le module nom_projet)
- cvs update (met à jour les fichiers de la copie de travail en local)
- cvs status -v nom_fichier (visualise l'état et les noms de versions symboliques du fichier)
- cvs -n update (idem que cvs status mais les informations sont plus condensées)
- cvs add -m (ajout de la procédure d'installation" INSTALL, ajoute le fichier INSTALL)
- cvs remove -f nom_fichier (supprime physiquement et dans la base CVS nom_fichier), pour être validée cette commande devra être suivie d'un cvs commit
- cvs commit -m "première version" index.html (archive la version dans CVS)
- cvs export -k v -d version_prod -r STABLE-V1_1 nom_projet (extrait une copie du module nom_projet dans le répertoire projet_v1_1 sans les répertoires de gestion utilisés par CVS)
- cd nom_projet/srv_server & cvs tag SRV-V1_0 (défini le nom symbolique SRV-V1_0 pour tous les fichiers de nom_projet/srv_server)
- cvs co -r SRV-V1_0 nom_projet/srv_server (récupère les fichiers ayant le tag SRV-V1_0 de nom_projet/srv_server)
- cvs rtag SRV-V2_0 nom_projet (défini le nom symbolique SRV-V2_0 à la dernière version présente dans la base des fichiers du module nom_projet)
- cvs diff --ifdef=V1_2 -r1.1 -r1.3 index.html (affiche les différences entre les versions 1.1 et 1.3 en séparant les modifications par le symbole préprocesseur V1_2)
- cvs rdiff -s -r STABLE-V1_0 nom_projet (résume les différences entre la version STABLE-V1_0 et la dernière version en base)
- cvs rdiff -u -r STABLE-V1_0 nom_projet (visualise les différences)
- cvs release -d nom_projet (vérifie que toutes vos modifications sont archivées et indique à CVS que vous n'utilisez plus votre copie de travail)
TABLE-V1_0 et la dernière version en base) - cvs rdiff -u -r STABLE-V1_0 nom_projet (visualise les différences)
- cvs release -d nom_projet (vérifie que toutes vos modifications sont archivées et indique à CVS que vous n'utilisez plus votre copie de travail)
Le modèle de CVS est un modèle centralisé, où un serveur central regroupe toutes les sources, mais il existe aussi des logiciels décentralisés comme Bazaar, Darcs, Git, Mercurial, Fossil ou Monotone, tous ces derniers étant des logiciels libres.
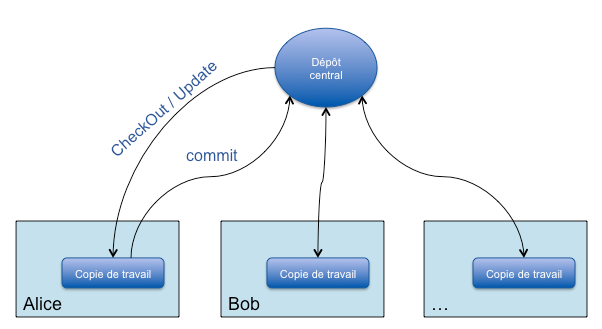
les types d'outil de gestion de version Publié le Mercredi 30 Mars 2011 à 15:43:29Rappelons tout d’abord le principe de fonctionnement de version (et de tous les systèmes de gestion de version non-distribués) afin de bien saisir les différences entre distribué et centralisé.
Subversion est donc composé d’un dépôt unique sur un serveur où se trouve l’ensemble des fichiers, de leurs versions ainsi que des branches qui permettent de gérer plusieurs versions du projet en parallèle.
Les développeurs (Alice et Bob par exemple) récupèrent une version du projet sur leur poste de travail (avec la commande checkout) pour pouvoir commencer à travailler dessus. Au quotidien, ils mettent à jour leur copie de travail local (update) depuis le serveur Subversion et renvoient leurs modifications (commit) vers ce même serveur. Ce mode de fonctionnement permet aux développeurs de travailler en parallèle sur le projet, de partager leurs modifications et de versionner les fichiers qu’ils modifient.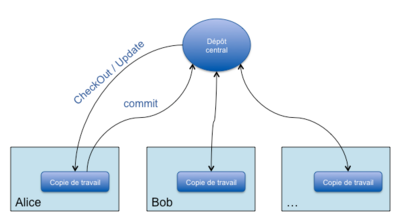
Shéma montre le principe de fonctionnemet de logiciel centralisé
Modèle Décentralisé
Lorsque l’on parle de gestion de version distribuée, cela signifie que le dépôt de fichier n’est plus unique sur un serveur mais que chaque développeur possède son propre dépôt. Chacun de ces dépôts contient l’ensemble des versions des fichiers. C’est de ce principe que découle toutes les autres fonctionnalités d’outils comme Git, Mercurial ou encore Bazaar. Pour illustrer cet article, les exemples s’appuieront sur Git. Même s’ils diffèrent dans le détail, les principes de dépôts multiples et d’échange entre ces dépôts restent globalement les mêmes pour chacun de ces outils.Exemple : Git
Git est un projet initié en 2005 par Linus Torvalds lorsque la licence du précédent gestionnaire de versions utilisé pour le noyau Linux (BitKeeper) ne lui permettait plus de l’utiliser gratuitement. Il est rapidement devenu une référence sur le sujet et on le comprend vite lorsque l’on s’intéresse à l’écosystème qui gravite autour du développement du noyau Linux : une communauté répartie tout autour du globe et un nombre important de branches qui vivent en parallèlePrincipe de Fonctionnement de Git:
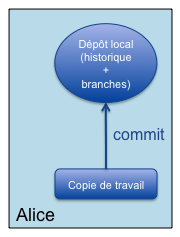
Commençons par l’initialisation d’un projet géré à l’aide de Git par un développeur seul (Alice). Celle-ci travaille sur sa copie de travail locale, comme avec Subversion, mais avec un dépôt local cette fois-ci :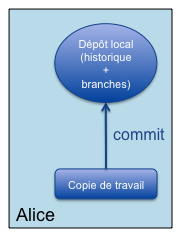 Shéma montre le principe de fonctionnement de GitAlice initialise son dépôt personnel sur son poste et enregistre ses modifications sur celui-ci. Pas besoin d’accès à un serveur (mode déconnecté).
Shéma montre le principe de fonctionnement de GitAlice initialise son dépôt personnel sur son poste et enregistre ses modifications sur celui-ci. Pas besoin d’accès à un serveur (mode déconnecté).1 2 3
git init # initialisation du dépôt git add ... # ajout de fichiers git commit -a # commit des modifications/ajouts dans le dépôt